1. 접속자 대기열 시스템 (Spring WebFlux + Redis)
1.1 프로젝트 설명
- 접속자 대기열 시스템입니다.
- 이벤트 티켓 예매와 같은 이커머스에서 주로 사용됩니다. 특정 시간대에 이벤트가 발생하게 되면 사용자가 많이 몰리게 되면 트래픽이 급겹하게 몰리게 됩니다.
- 짧은 시간안에 이런 트래픽을 처리 하기 위해서는 특정 기술이 필요합니다. 단순한 Spring MVC가 아닌 Spring Webflux와 Redis를 활용합니다.
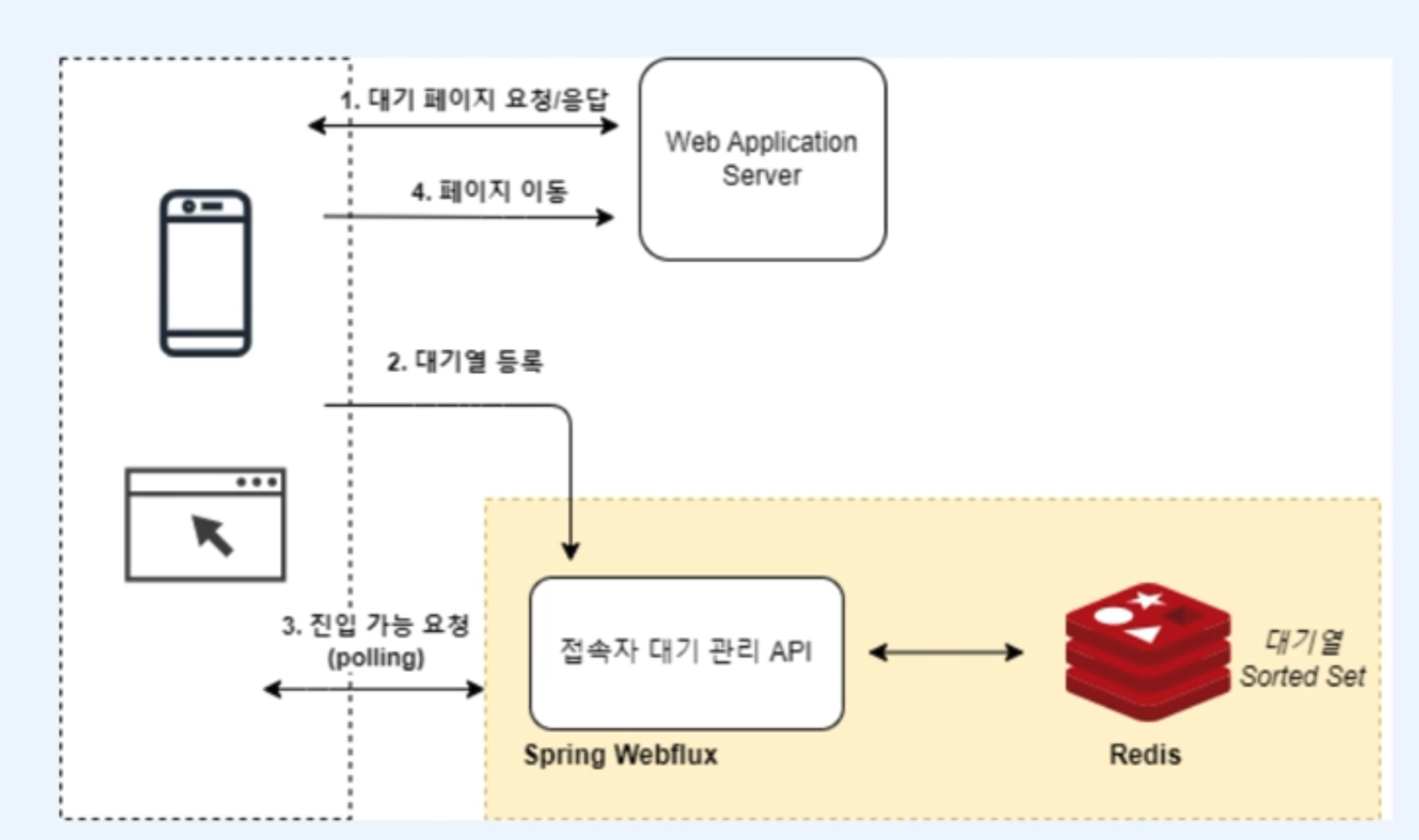
Spring WebFlux와 Redis가 어떻게 대기열을 관리하는지 보여줍니다.
- 1단계: 대기 페이지 요청/응답
- 사용자가 웹 애플리케이션 서버에 접속을 시도하면, 서버는 사용자에게 대기 페이지를 응답합니다. 이 대기 페이지에서 사용자는 대기열에 등록됩니다.
- 2단계: 대기열 등록
- 사용자가 대기열에 등록되면, Spring WebFlux 기반의 접속자 대기 관리 API가 호출됩니다. 이 API는 사용자를 Redis의 Sorted Set에 등록하여 대기열에서 사용자의 위치를 관리합니다.
- Redis는 Sorted Set을 사용하여, 사용자의 순서를 숫자로 관리하며, 정렬된 방식으로 대기열을 처리합니다.
- 3단계: 진입 가능 요청 (Polling)
- 사용자는 일정한 시간 간격(예: 5초 또는 10초)으로 대기열 상태를 폴링(Polling) 방식으로 확인합니다. WebFlux는 비동기 방식으로 대기열 상태를 처리하며, 사용자가 순번에 따라 서비스에 진입할 수 있는지 여부를 응답합니다.
- 4단계: 페이지 이동
- 사용자가 대기열에서 순번에 따라 접속 가능 상태가 되면, 대기 페이지에서 실제 서비스 페이지로 이동하게 됩니다. 이때, Spring WebFlux가 이를 처리하며, 사용자는 대기열에서 빠집니다.
Redis 역할
Redis는 Sorted Set을 사용하여 각 사용자의 대기 순서를 기록하고 관리합니다. Sorted Set의 장점은 각 요소가 고유한 점수(대기 순번)를 가지며, 이를 기준으로 빠르게 순서를 정렬하고 관리할 수 있다는 것입니다. 이는 대기열 시스템에서 사용자 순번 관리에 매우 효율적입니다.
Spring WebFlux 역할
Spring WebFlux는 비동기 논블로킹 방식으로, 다수의 사용자 요청을 처리하는데 적합한 구조를 제공합니다. 특히, Polling과 같이 사용자가 일정 간격으로 대기 상태를 확인하는 상황에서는 매우 적합한 기술입니다. Spring WebFlux는 서버 자원을 효율적으로 사용하여 대규모 동시 접속자 처리에 효과적입니다.
기술 스택
- Java 17(LTS)
- Spring Boot 3
- Redis 6
- MySQL8
- IntelliJ Idea Ultimate
2. 기반 기술 설명
2.1 In-memory DB: Redis
Redis는 오픈 소스, 고성능의 인메모리 데이터베이스로, 주로 캐시, 세션 관리, 메시지 브로커, 대기열 처리 등에 사용됩니다. 데이터는 메모리에 저장되어 매우 빠른 속도로 데이터를 읽고 쓸 수 있으며, 서버 간 데이터 공유가 필요할 때도 활용할 수 있습니다.
- 인메모리 데이터베이스: 모든 데이터가 메모리에 저장되므로 빠른 성능을 제공합니다.
- 데이터 구조: Redis는 문자열(String), 리스트(List), 해시(Hash), 집합(Set), 정렬된 집합(Sorted Set) 등 다양한 데이터 구조를 지원합니다.
- 대기열 관리: Redis의 Sorted Set(정렬된 집합)은 대기열 시스템에 적합한 데이터 구조로, 순서를 유지하며 사용자들의 대기 위치를 관리할 수 있습니다.
- Persistence(영속성): Redis는 기본적으로 메모리 기반이지만, 지속적인 저장을 위해 디스크에 데이터를 기록할 수 있는 기능도 제공합니다.
2.2 Reactive Programming: Spring WebFlux
Spring WebFlux는 Spring 5에서 도입된 리액티브 프로그래밍을 지원하는 비동기 논블로킹(non-blocking) 웹 프레임워크입니다. 주로 고성능 네트워크 애플리케이션을 구축할 때 사용됩니다.
- 비동기 & 논블로킹: 요청을 받으면 해당 요청이 완료될 때까지 스레드를 점유하지 않으므로, 매우 효율적인 자원 사용을 가능하게 합니다. 동시에 많은 요청을 처리할 수 있는 장점이 있습니다.
- Reactive Streams: Spring WebFlux는 리액티브 스트림 사양을 따르며, 데이터 흐름을 비동기적으로 처리하고, 반응형으로 시스템을 구성할 수 있습니다.
- 적용 분야: WebFlux는 많은 동시 접속자와 빠른 응답이 요구되는 시스템에 적합합니다. 예를 들어, 실시간 데이터 스트리밍이나 대규모 대기열 시스템에 매우 적합합니다.
3. 백엔드 서비스 아키텍처의 확장 흐름
- 백엔드 서비스가 확장하는 흐름과 in-memory DB와 reactive programming이 활용되는지 점진적인 Case로 살펴보겠습니다.
- 서비스가 유지하고 그리고 확장하는 상황에서 어떤 흐름으로 아키텍처가 변경 및 확장되는지 살펴 봅니다.
Case 1: 간단한 커뮤니티 서비스
이 경우, 클라이언트가 웹 애플리케이션에 데이터를 요청하면, 웹 애플리케이션은 데이터베이스에 쿼리를 보내고 데이터를 반환하는 단순한 아키텍처입니다.
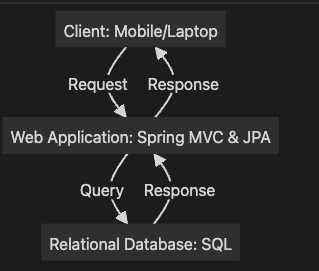
graph TD
Client[Client: Mobile/Laptop] -->|Request| WebApp[Web Application: Spring MVC & JPA]
WebApp -->|Query| DB[Relational Database: SQL]
DB -->|Response| WebApp
WebApp -->|Response| Client추가 설명:
- Client는 데이터를 요청하고, Web Application은 데이터를 처리합니다.
- Relational Database는 데이터를 저장하고 관리하는 역할을 하며, Spring JPA를 통해 데이터베이스와 상호작용합니다.
- 이 구조는 소규모 커뮤니티 서비스에 적합하지만, 트래픽이 많아지면 성능 문제가 발생할 수 있습니다.
Case 2: 트래픽 증가로 인한 정적 파일 처리 문제 해결
트래픽이 증가하면 정적 파일(이미지, 비디오 등)이 서버 부하의 주요 원인이 될 수 있습니다. 이때 CDN을 사용해 정적 파일을 별도로 처리하고, 웹 애플리케이션 서버는 동적 콘텐츠만 처리하도록 구성할 수 있습니다.

graph TD
Client[Client: Mobile/Laptop] -->|Request| WebApp[Web Application: Spring MVC & JPA]
Client -->|Static Content| CDN[CDN: Content Delivery Network]
CDN -->|Files| File[File Storage: Image/Video]
WebApp -->|Query| DB[Relational Database: SQL]
DB -->|Response| WebApp
WebApp -->|Response| Client추가 설명:
- CDN을 사용하면 클라이언트가 웹 애플리케이션을 거치지 않고 정적 콘텐츠(이미지, 비디오 등)를 빠르게 다운로드할 수 있습니다.
- File Storage에 정적 파일을 저장하고, CDN은 네트워크 지리적으로 가까운 곳에서 파일을 제공해 성능을 향상시킵니다.
- 웹 애플리케이션 서버는 동적 데이터만 처리하게 되어 서버 부하를 줄일 수 있습니다.
Case 3: Web Application Server의 수평 확장 (Scale-out)
정적 파일을 CDN을 통해 처리했음에도 불구하고, 웹 애플리케이션 서버가 처리할 수 있는 트래픽을 넘어서게 되면, 수평 확장을 통해 여러 대의 웹 애플리케이션 서버를 추가해 부하를 분산할 수 있습니다.

graph TD
Client[Client: Mobile/Laptop] -->|Request| WebApp1[Web Application 1]
Client -->|Request| WebApp2[Web Application 2]
Client -->|Request| WebApp3[Web Application 3]
WebApp1 -->|Query| DB[Relational Database: SQL]
WebApp2 -->|Query| DB[Relational Database: SQL]
WebApp3 -->|Query| DB[Relational Database: SQL]추가 설명:
- 여러 Web Application 서버가 수평 확장(Scale-out)되어 클라이언트 요청을 처리할 수 있습니다.
- 서버 간 상태 관리(Session State)를 해결하기 위해, 세션 데이터를 Redis 또는 세션 클러스터로 관리하거나, JWT로 클라이언트 쪽에서 상태를 관리할 수 있습니다.
- 여러 서버가 같은 데이터베이스를 사용하게 되므로, 데이터베이스 부하도 고려해야 합니다.
Case 4: Load Balancer를 통한 동적 요청 분배
여러 개의 웹 애플리케이션 서버가 수평 확장되었을 때, 로드 밸런서를 통해 클라이언트 요청을 각 서버로 동적으로 분배합니다.

graph TD
Client[Client: Mobile/Laptop] -->|Request| LB[Load Balancer]
LB -->|Distribute| WebApp1[Web Application 1]
LB -->|Distribute| WebApp2[Web Application 2]
LB -->|Distribute| WebApp3[Web Application 3]
WebApp1 -->|Query| DB[Relational Database: SQL]
WebApp2 -->|Query| DB[Relational Database: SQL]
WebApp3 -->|Query| DB[Relational Database: SQL]추가 설명:
- 로드 밸런서는 클라이언트 요청을 여러 웹 애플리케이션 서버로 분배하여 트래픽을 관리합니다.
- 분배 방식에는 여러 가지 방법이 있습니다. 예를 들어, 라운드 로빈(순서대로 분배), 최소 연결(가장 적은 연결 수를 가진 서버로 분배), IP 해시(특정 클라이언트가 항상 같은 서버로 연결)를 사용할 수 있습니다.
- 상태 비저장 방식(stateless) 웹 애플리케이션이 확장성 측면에서 유리합니다. 이는 서버 간의 상태 동기화가 필요 없기 때문입니다.
Case 5: 캐시 시스템을 통한 데이터베이스 부하 감소
서버가 수평 확장된 상황에서 데이터베이스 부하가 증가할 수 있습니다. 이를 해소하기 위해 캐시 시스템을 도입하여 자주 사용되는 데이터를 미리 저장하고, 데이터베이스 접근을 줄이는 방법을 사용할 수 있습니다.
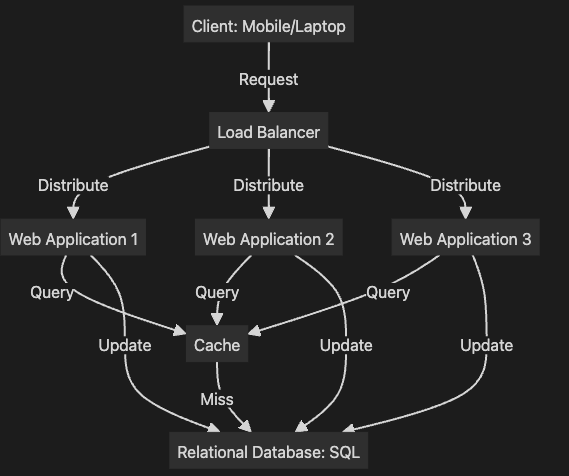
graph TD
Client[Client: Mobile/Laptop] -->|Request| LB[Load Balancer]
LB -->|Distribute| WebApp1[Web Application 1]
LB -->|Distribute| WebApp2[Web Application 2]
LB -->|Distribute| WebApp3[Web Application 3]
WebApp1 -->|Query| Cache[Cache]
WebApp2 -->|Query| Cache[Cache]
WebApp3 -->|Query| Cache[Cache]
Cache -->|Miss| DB[Relational Database: SQL]
WebApp1 -->|Update| DB[Relational Database: SQL]
WebApp2 -->|Update| DB[Relational Database: SQL]
WebApp3 -->|Update| DB[Relational Database: SQL]추가 설명:
- 캐시(Cache)는 자주 사용되지만 변경되지 않는 데이터를 저장하여 데이터베이스 부하를 줄이는 데 사용됩니다.
- 캐시가 없을 경우(캐시 미스), 웹 애플리케이션은 데이터베이스에서 데이터를 조회하고, 이를 캐시에 저장합니다.
- 캐시 일관성 문제를 해결하기 위해, 캐시 데이터의 유효 기간(TTL)을 설정하거나, Write-through 전략(데이터베이스에 쓰면 캐시에도 쓰는 방식)을 사용할 수 있습니다.
- 캐시 히트율을 높이기 위한 적절한 캐싱 전략이 필요합니다. 예를 들어, 자주 조회되지만 자주 변경되지 않는 데이터(예: 상품 목록, 사용자 프로필 등)를 캐시에 저장하는 것이 효과적입니다.
추가 고려 사항:
- 로드 밸런서의 추가 기능: 로드 밸런서는 단순한 트래픽 분배 외에도 SSL 종료, 트래픽 암호화, 장애 복구(Failover) 등의 기능을 제공할 수 있습니다.
- 데이터베이스 스케일링: 데이터베이스 스케일링에는 샤딩(Sharding) 또는 복제(Replication) 전략을 사용할 수 있습니다. 이를 통해 더 많은 트래픽을 처리할 수 있습니다.
- 캐시 사용 시 고려사항: Redis나 Memcached와 같은 인메모리 데이터베이스를 사용하여 높은 성능을 얻을 수 있지만, 캐시 데이터의 갱신 주기와 일관성 문제를 해결하는 것이 중요합니다.
결론:
각 단계에서 트래픽 증가에 대응하고 성능을 최적화하기 위한 여러 방안을 제시하였습니다. 특히, 웹 애플리케이션의 수평 확장, 로드 밸런서, 캐시 사용 등은 시스템 성능을 극대화하는 데 핵심적인 역할을 하며, 각 솔루션의 세부적인 고려 사항을 통해 성능과 확장성을 확보할 수 있습니다.
웹 어플리케이션 관점에서 톺아보기
Case 1: Spring MVC의 다수의 OS 쓰레드 기반 요청 처리 구조
Spring MVC는 Thread-per-request 모델을 따르며, 각 요청에 대해 새로운 스레드가 생성되거나 기존 스레드 풀에서 스레드가 할당됩니다. 많은 요청이 있을 경우, 스레드가 많이 필요하고, 외부 요청(예: DB 쿼리 등)이 발생하면 Blocking I/O로 인해 스레드가 잠시 대기 상태가 됩니다. 이는 대규모 트래픽 상황에서 메모리와 CPU 자원의 소모를 가중시킵니다.

graph TD
Client[Client: Mobile/Laptop] -->|Request| LB[Load Balancer]
LB -->|Distribute| WebApp1[Web Application 1]
LB -->|Distribute| WebApp2[Web Application 2]
LB -->|Distribute| WebApp3[Web Application 3]
WebApp1 -->|Process| Thread1_1[Thread 1]
WebApp1 -->|Process| Thread1_2[Thread 2]
WebApp1 -->|Process| Thread1_3[Thread ...]
WebApp2 -->|Process| Thread2_1[Thread 1]
WebApp2 -->|Process| Thread2_2[Thread 2]
WebApp2 -->|Process| Thread2_3[Thread ...]
WebApp3 -->|Process| Thread3_1[Thread 1]
WebApp3 -->|Process| Thread3_2[Thread 2]
WebApp3 -->|Process| Thread3_3[Thread ...]추가 설명:
- 로드 밸런서는 여러 웹 애플리케이션 서버로 트래픽을 분산합니다.
- 각 Web Application 서버는 요청을 처리할 때 스레드 풀(Thread Pool)에서 스레드를 할당받습니다. 요청 수가 많아지면 더 많은 스레드가 할당되어 메모리 자원이 소모됩니다.
- Blocking I/O 발생: 스레드가 외부 리소스(DB 등)와 통신할 때, Blocking이 발생하여 스레드가 대기 상태가 되고, 새로운 요청을 처리할 수 없게 됩니다.
- 결과: 대규모 트래픽에서 성능 저하가 발생할 수 있습니다.
Case 2: Spring MVC의 Thread-per-request 구조 문제점
클라이언트가 웹 애플리케이션에 요청을 보내면, Spring MVC는 요청을 처리하기 위해 스레드를 할당합니다. 하지만, 외부 요청(DB 또는 API 호출)에서 Blocking이 발생하게 되면, 스레드는 요청이 완료될 때까지 대기 상태에 놓이게 됩니다.
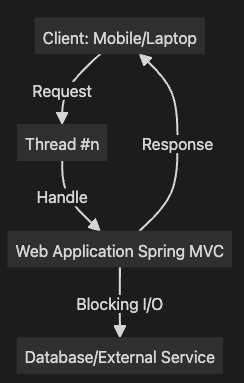
graph TD
Client[Client: Mobile/Laptop] -->|Request| ThreadN[Thread #n]
ThreadN -->|Handle| WebApp[Web Application Spring MVC]
WebApp -->|Blocking I/O| DB[Database/External Service]
WebApp -->|Response| Client추가 설명:
- Blocking I/O는 스레드가 외부 리소스(예: DB)와 통신할 때 발생하며, 스레드는 이 동안 대기 상태로 유지됩니다.
- 많은 수의 Blocking 상태 스레드가 발생하면, 새로운 요청을 처리할 스레드가 부족해지고, 서버 성능이 저하됩니다.
- Thread-per-request 모델은 많은 수의 요청을 처리하는 상황에서 비효율적일 수 있습니다.
Case 3: Spring WebFlux를 통한 Non-blocking I/O 처리
Spring WebFlux는 Reactor 라이브러리를 사용하여 Non-blocking I/O를 처리합니다. 이 구조에서는 Event Loop가 요청을 처리하며, Non-blocking 스레드를 통해 많은 요청을 효율적으로 처리할 수 있습니다. 특히, 외부 요청(DB 등)에서도 스레드가 대기 상태에 빠지지 않고, 다른 요청을 처리할 수 있게 됩니다.
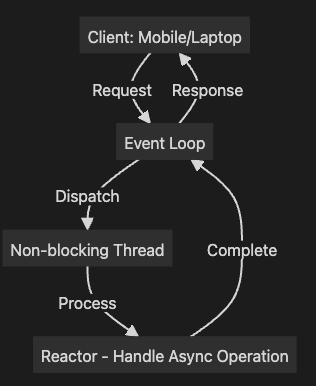
graph TD
Client[Client: Mobile/Laptop] -->|Request| EventLoop[Event Loop]
EventLoop -->|Dispatch| ThreadN[Non-blocking Thread]
ThreadN -->|Process| Reactor[Reactor - Handle Async Operation]
Reactor -->|Complete| EventLoop
EventLoop -->|Response| Client추가 설명:
- Event Loop는 클라이언트 요청을 받으면, Non-blocking 스레드로 요청을 할당합니다.
- Reactor는 비동기적으로 요청을 처리하며, Non-blocking I/O를 통해 외부 리소스와 통신합니다.
- Blocking 상태 없음: 외부 리소스(DB, API 등)와 통신 시에도 Blocking이 발생하지 않아, 적은 리소스로 많은 요청을 처리할 수 있습니다.
- Reactor는 Backpressure 제어를 통해 처리할 수 있는 데이터 양을 조절하고, 시스템이 과부하에 걸리지 않도록 관리합니다.
- 비교: WebFlux는 적은 수의 스레드로 많은 요청을 처리할 수 있으므로, 대규모 트래픽 상황에서도 자원을 효율적으로 사용할 수 있습니다.
추가 설명 보완
Spring MVC와 WebFlux 비교:
- Spring MVC는 Thread-per-request 방식으로, 요청이 들어오면 스레드가 할당되며, 외부 요청에서 Blocking이 발생하면 스레드가 대기 상태로 빠집니다.
- Spring WebFlux는 Event-driven, Non-blocking I/O 방식을 사용하여, 많은 요청을 효율적으로 처리할 수 있습니다. 스레드 대기 상태가 없어지고, 자원을 더 적게 사용하면서도 대규모 트래픽을 처리할 수 있습니다.
추가적인 고려 사항:
- WebFlux 한계: WebFlux는 I/O 바운드 작업에서는 매우 효율적이지만, CPU 바운드 작업에서는 큰 이점을 제공하지 않습니다. 따라서 WebFlux의 사용은 I/O 처리에 적합한 경우에 주로 사용됩니다.
- Reactor의 Backpressure 처리: WebFlux는 Reactor를 통해 Backpressure(데이터 처리 속도 제어)를 관리합니다. 이는 시스템 과부하를 방지하며, 데이터 흐름을 효율적으로 제어합니다.
'프레임워크 > 자바 스프링' 카테고리의 다른 글
| Webflux - spring mvc vs webflux (1) | 2024.09.18 |
|---|---|
| Webflux 소개 (0) | 2024.09.17 |
| 대규모 트래픽 게시판 구축 시리즈 #14: 배포 자동화 (1) | 2024.09.07 |
| 대규모 트래픽 게시판 구축 시리즈 #13: 알림 서비스 구현과 통합 - AWS SNS 및 Slack (0) | 2024.09.07 |
| 대규모 트래픽 게시판 구축 시리즈 #12: 성능 테스트 (5) | 2024.09.07 |