Spring MVC와 Spring WebFlux 성능 비교를 위한 프로젝트 구성
이번 포스트에서는 Spring MVC와 Spring WebFlux를 사용해 간단한 웹 애플리케이션을 구현하고, 두 프레임워크의 성능을 비교하는 방법을 다룹니다. 이 글에서는 각 프로젝트의 설정 및 핵심 코드에 대해 자세히 설명하겠습니다. 특히 동기식과 비동기식 처리 방식의 차이를 이해하는 데 중점을 두겠습니다.
1. Docker를 이용한 환경 구성
성능 비교를 위해 MySQL과 Redis가 필요하므로, Docker를 사용하여 각각의 컨테이너를 설정합니다.
MySQL과 Redis 컨테이너 실행
docker run --name mysql-r2dbc -e MYSQL_ROOT_PASSWORD=r2dbc -e MYSQL_DATABASE=mvc -p 3306:3306 -d mysql:8.0
docker run --name redis -p 6379:6379 -d redis:6.2컨테이너가 정상적으로 실행되는지 확인하려면 docker ps 명령어를 사용하여 상태를 체크합니다:
CONTAINER ID IMAGE COMMAND STATUS PORTS NAMES
31f05f8bf1bd mysql:8.0 "docker-entrypoint.s…" Up 0.0.0.0:3306->3306/tcp, 33060/tcp mysql-r2dbc
b29f75309e64 redis:6.2 "docker-entrypoint.s…" Up 0.0.0.0:6379->6379/tcp redis이제 MySQL과 Redis가 준비되었으므로, 이 데이터베이스와 캐시를 사용하는 두 가지 프로젝트를 구성합니다.
2. Spring MVC 프로젝트 구성
Spring MVC는 널리 사용되는 동기식 웹 프레임워크로, 요청이 들어오면 해당 요청을 처리할 스레드를 할당하고, 스레드는 작업이 완료될 때까지 블로킹(대기)됩니다. 이는 간단한 애플리케이션이나 낮은 트래픽의 서비스에서 적합하지만, 트래픽이 급증할 경우 성능 저하가 발생할 수 있습니다.
2.1. Gradle 의존성 설정
plugins {
id 'java'
id 'org.springframework.boot' version '3.3.4'
id 'io.spring.dependency-management' version '1.1.6'
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web' // Spring MVC 의존성
implementation 'org.springframework.boot:spring-boot-starter-data-jpa' // JPA
implementation 'org.springframework.boot:spring-boot-starter-data-redis' // Redis 의존성
runtimeOnly 'com.mysql:mysql-connector-j' // MySQL 연결
compileOnly 'org.projectlombok:lombok' // 롬복
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test' // 테스트 관련 의존성
}이 프로젝트에서는 MySQL을 데이터베이스로 사용하고, Redis는 캐시로 활용합니다. 이 설정은 spring-boot-starter-web, spring-boot-starter-data-jpa, 그리고 spring-boot-starter-data-redis와 같은 핵심 의존성을 포함하고 있습니다.
2.2. application.yml 설정
server:
port: 9000
tomcat:
max-connections: 10000
accept-count: 1000
threads:
max: 3000
min-spare: 1000
spring:
datasource:
url: jdbc:mysql://localhost:3306/mvc
username: root
password: r2dbc
data:
redis:
host: localhost
port: 6379
jpa:
hibernate:
ddl-auto: update- Tomcat 설정:
max-connections: Tomcat 서버가 허용할 수 있는 최대 연결 수.threads.max: 최대 스레드 수를 3000으로 설정하여 동시 요청을 처리할 수 있게 조정.
- JPA 및 MySQL 설정:
spring.datasource에 MySQL 정보를 설정하고,ddl-auto: update옵션을 통해 엔티티에 맞춰 테이블을 자동으로 업데이트합니다. - Redis 설정: 로컬에서 Redis가 6379 포트로 실행되고 있으므로 이에 맞춘 설정이 되어 있습니다.
2.3. Spring MVC 핵심 코드
Spring MVC 애플리케이션은 요청이 들어오면 해당 요청을 처리하고, MySQL에서 데이터를 읽거나 Redis에서 캐시된 데이터를 가져오는 흐름으로 동작합니다.
@SpringBootApplication
@RestController
@RequiredArgsConstructor
public class MvcApplication implements ApplicationListener<ApplicationReadyEvent> {
private final RedisTemplate<String, String> redisTemplate;
private final UserRepository userRepository;
public static void main(String[] args) {
SpringApplication.run(MvcApplication.class, args);
}
@GetMapping("/health")
public Map<String, String> health() {
return Map.of("health", "ok");
}
@GetMapping("/users/1/cache")
public Map<String, String> getCachedUser() {
var name = redisTemplate.opsForValue().get("users:1:name");
var email = redisTemplate.opsForValue().get("users:1:email");
return Map.of("name", name == null ? "" : name, "email", email == null ? "" : email);
}
@GetMapping("/users/{id}")
public User getUser(@PathVariable Long id) {
return userRepository.findById(id).orElse(new User());
}
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
var NAME = "greg";
var EMAIL_DOMAIN = "gmail.com";
redisTemplate.opsForValue().set("users:1:name", NAME);
redisTemplate.opsForValue().set("users:1:email", "{}@{}".formatted(NAME, EMAIL_DOMAIN));
Optional<User> user = userRepository.findById(1L);
if(user.isEmpty()){
userRepository.save(User.builder().name(NAME).email("{}@{}".formatted(NAME, EMAIL_DOMAIN)).build());
}
}
}주어진 MvcApplication 클래스는 Spring Boot 애플리케이션으로, REST API를 제공합니다. 여러 가지 엔드포인트를 정의하여 Redis와 MySQL을 사용하여 데이터를 처리합니다. 각 엔드포인트는 간단한 시스템 상태를 반환하거나, 사용자 데이터를 데이터베이스 또는 Redis에서 조회하고 캐시하는 기능을 합니다. 아래에 각 엔드포인트에 대한 설명을 드리겠습니다.
2.3.1. /health 엔드포인트 (시스템 상태 확인)
@GetMapping("/health")
public Map<String, String> health() {
return Map.of("health", "ok");
}- 설명:
- 이 엔드포인트는 애플리케이션의 상태를 확인하는 용도로 사용됩니다.
/healthURL로 요청을 보내면,{ "health": "ok" }라는 JSON 응답을 반환합니다.- 목적: 주로 애플리케이션이 정상적으로 실행되고 있는지 간단하게 확인할 때 유용합니다. 모니터링 도구에서 이 엔드포인트를 이용해 애플리케이션 상태를 주기적으로 확인할 수 있습니다.
2.3.2 /users/1/cache 엔드포인트 (Redis 캐시에서 사용자 정보 조회)
@GetMapping("/users/1/cache")
public Map<String, String> getCachedUser() {
var name = redisTemplate.opsForValue().get("users:1:name");
var email = redisTemplate.opsForValue().get("users:1:email");
return Map.of("name", name == null ? "" : name, "email", email == null ? "" : email);
}- 설명:
- 이 엔드포인트는 Redis에서 사용자
ID: 1에 해당하는 캐시된 정보를 조회합니다. - Redis에서
"users:1:name"와"users:1:email"이라는 키로 저장된 값(이름과 이메일)을 가져와서 반환합니다. - 만약 해당 값이 캐시에 없다면 빈 문자열을 반환합니다.
- 목적: Redis는 캐시 메커니즘으로 사용되므로, 데이터베이스를 매번 조회하지 않고 빠르게 사용자 데이터를 제공하기 위해 캐시된 데이터를 조회하는 데 사용됩니다.
- 이 엔드포인트는 Redis에서 사용자
2.3.3 /users/{id} 엔드포인트 (MySQL 데이터베이스에서 사용자 조회)
@GetMapping("/users/{id}")
public User getUser(@PathVariable Long id) {
return userRepository.findById(id).orElse(new User());
}- 설명:
- 이 엔드포인트는 URL 경로에 제공된 사용자
ID를 기반으로 MySQL 데이터베이스에서 해당 사용자를 조회합니다. userRepository.findById(id)는 MySQL에서 사용자를 찾으며, 사용자가 없을 경우 빈User객체를 반환합니다.- 목적: MySQL 데이터베이스에서 실제 사용자 데이터를 조회합니다. 데이터베이스에 데이터가 없다면 기본적으로 빈
User객체를 반환합니다. 이 엔드포인트는 실시간 사용자 데이터를 가져오는 데 사용됩니다.
- 이 엔드포인트는 URL 경로에 제공된 사용자
2.3.4. onApplicationEvent 메서드 (애플리케이션 초기화 시 Redis 캐시 설정)
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
var NAME = "greg";
var EMAIL_DOMAIN = "gmail.com";
redisTemplate.opsForValue().set("users:1:name", NAME);
redisTemplate.opsForValue().set("users:1:email", "{}@{}".formatted(NAME, EMAIL_DOMAIN));
Optional<User> user = userRepository.findById(1L);
if (user.isEmpty()) {
userRepository.save(User.builder().name(NAME).email("{}@{}".formatted(NAME, EMAIL_DOMAIN)).build());
}
}- 설명:
- 이 메서드는 애플리케이션이 시작된 후 실행되며, 사용자 정보를 Redis에 미리 캐싱하고, 데이터베이스에 사용자
ID: 1의 정보가 없는 경우 새로운 사용자를 생성하여 저장합니다. - Redis에 사용자
ID: 1의 이름과 이메일을 캐시로 저장합니다. - 데이터베이스에 사용자
ID: 1이 없으면, 사용자greg를 생성하여 MySQL에 저장합니다. - 목적: 애플리케이션 초기화 시 Redis에 사용자 정보를 미리 캐싱해두고, 데이터베이스에 해당 사용자가 없는 경우 새로 생성하여 저장하는 초기화 작업입니다.
- 이 메서드는 애플리케이션이 시작된 후 실행되며, 사용자 정보를 Redis에 미리 캐싱하고, 데이터베이스에 사용자
전체 흐름 요약:
/health: 애플리케이션의 상태를 확인하는 간단한 엔드포인트.{ "health": "ok" }응답을 반환./users/1/cache: Redis에 캐시된 사용자ID: 1의 이름과 이메일 정보를 조회. 캐시된 데이터가 없으면 빈 문자열을 반환./users/{id}: MySQL 데이터베이스에서 사용자ID에 해당하는 정보를 조회. 사용자가 없으면 빈User객체를 반환.onApplicationEvent: 애플리케이션이 처음 실행될 때 사용자greg정보를 Redis에 캐싱하고, 데이터베이스에 사용자가 없을 경우 새로 생성하여 저장.
3. Spring WebFlux 프로젝트 구성
Spring WebFlux는 비동기 논블로킹 방식으로 작동하며, 동시에 많은 요청을 처리할 수 있습니다. Reactor를 기반으로 동작하며, 적은 스레드로도 높은 성능을 낼 수 있는 장점이 있습니다.
3.1. Gradle 의존성 설정
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-webflux' // WebFlux 의존성
implementation 'org.springframework.boot:spring-boot-starter-data-r2dbc' // R2DBC MySQL 연결
implementation 'org.springframework.boot:spring-boot-starter-data-redis-reactive' // Reactive Redis
runtimeOnly 'io.asyncer:r2dbc-mysql:1.0.2' // MySQL R2DBC 드라이버
testImplementation 'io.projectreactor:reactor-test'
}3.2. application.yml 설정
server:
port: 9010
spring:
r2dbc:
url: r2dbc:mysql://localhost:3306/r2dbc
username: root
password: r2dbc
data:
redis:
host: 127.0.0.1
port: 6379- R2DBC 설정: MySQL과 연결할 때는 R2DBC 드라이버를 사용하며,
r2dbc:mysql://형식의 URL을 사용합니다. - Reactive Redis 설정: Spring WebFlux에서는 비동기 방식의 Redis 사용을 위해
spring-boot-starter-data-redis-reactive를 사용하여 Redis와 연결합니다.
3.3. Spring WebFlux 핵심 코드
Spring WebFlux에서는 비동기 방식으로 데이터베이스와 Redis에서 데이터를 조회합니다. Mono와 Flux를 사용하여 논블로킹 방식으로 데이터 처리가 가능합니다.
package com.example.webflux;
import lombok.*;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.LastModifiedDate;
import org.springframework.data.redis.connection.ReactiveRedisConnectionFactory;
import org.springframework.data.redis.core.ReactiveRedisTemplate;
import org.springframework.data.relational.core.mapping.Table;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Mono;
import java.time.LocalDateTime;
import java.util.Map;
@SpringBootApplication
@RestController
@RequiredArgsConstructor
public class WebfluxApplication {
private final ReactiveRedisTemplate<String, String> reactiveRedisTemplate;
private final UserRepository userRepository;
public static void main(String[] args) {
SpringApplication.run(WebfluxApplication.class, args);
}
@GetMapping("/health")
public Mono<Map<String, String>> health(){
return Mono.just(Map.of("health", "OK"));
}
@GetMapping("/users/1/cache")
public Mono<Map<String, String>> getCachedUser(){
var name = reactiveRedisTemplate.opsForValue().get("users:1:name");
var email = reactiveRedisTemplate.opsForValue().get("users:1:email");
return Mono.zip(name, email)
.map(i -> Map.of("name", i.getT1(), "meail", i.getT2()));
}
@GetMapping("users/{id}")
public Mono<User> getUser(@PathVariable Long id){
return userRepository.findById(id).defaultIfEmpty(new User());
}
}
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table(name = "users")
class User {
@Id
private Long id;
private String name;
private String email;
@CreatedDate
private LocalDateTime createdAt;
@LastModifiedDate
private LocalDateTime updatedAt;
}
interface UserRepository extends ReactiveCrudRepository<User, Long> {
}이 코드는 Spring WebFlux를 사용하여 비동기 방식으로 데이터를 처리하는 API 엔드포인트들을 정의하고 있습니다. 각각의 엔드포인트는 Mono를 사용하여 비동기적이고 논블로킹 방식으로 응답을 반환합니다. 아래에서 각 엔드포인트에 대한 설명을 드리겠습니다.
3.3.1. /health 엔드포인트 (시스템 상태 확인)
@GetMapping("/health")
public Mono<Map<String, String>> health() {
return Mono.just(Map.of("health", "OK"));
}- 설명:
- 이 엔드포인트는 애플리케이션의 상태를 확인하는 용도로 사용됩니다.
/health로 요청을 보내면{ "health": "OK" }라는 JSON 응답을 반환합니다.- Mono는 비동기적으로 데이터를 반환하기 위한 리액티브 타입으로, 여기서는 간단히
Mono.just()를 사용하여 즉시 응답을 반환합니다. - 목적: 주로 애플리케이션 상태를 확인할 때 사용됩니다. WebFlux에서는 이마저도 비동기적으로 처리할 수 있습니다.
3.3.2. /users/1/cache 엔드포인트 (Redis 캐시에서 사용자 정보 조회)
@GetMapping("/users/1/cache")
public Mono<Map<String, String>> getCachedUser() {
var name = reactiveRedisTemplate.opsForValue().get("users:1:name");
var email = reactiveRedisTemplate.opsForValue().get("users:1:email");
return Mono.zip(name, email)
.map(i -> Map.of("name", i.getT1(), "email", i.getT2()));
}- 설명:
- 이 엔드포인트는 사용자
ID: 1의 정보를 Redis에서 비동기적으로 가져옵니다. - Reactive Redis를 사용하여 Redis에서 이름과 이메일 정보를 조회하며,
Mono.zip()을 사용해 두 개의 비동기 결과를 병합합니다. Mono.zip(name, email)은 두 개의Mono객체를 하나의Mono로 결합한 후,map을 통해 데이터를 가공합니다.- 목적: Redis 캐시에서 비동기적으로 사용자 정보를 조회하고 반환하여, MySQL을 조회하지 않고도 빠르게 사용자 정보를 얻을 수 있습니다.
- 이 엔드포인트는 사용자
3.3.3. /users/{id} 엔드포인트 (MySQL 데이터베이스에서 사용자 조회)
@GetMapping("users/{id}")
public Mono<User> getUser(@PathVariable Long id) {
return userRepository.findById(id).defaultIfEmpty(new User());
}- 설명:
- 이 엔드포인트는 경로 변수로 받은 사용자
ID에 해당하는 사용자를 MySQL 데이터베이스에서 비동기적으로 조회합니다. userRepository.findById(id)는 비동기적으로 작동하는 리액티브 리포지토리 메서드이며, 조회된 사용자가 없을 경우defaultIfEmpty(new User())를 사용해 빈User객체를 반환합니다.- 목적: MySQL 데이터베이스에서 사용자 정보를 비동기적으로 조회하여 반환하며, WebFlux의 비동기 논블로킹 특성을 활용해 빠르고 효율적으로 처리합니다.
- 이 엔드포인트는 경로 변수로 받은 사용자
요약
이 코드에서는 Spring WebFlux와 Reactive Redis, Reactive MySQL을 사용하여 비동기적이고 논블로킹 방식으로 API를 구현했습니다. 모든 엔드포인트는 Mono 객체를 통해 비동기적으로 데이터를 처리하고, 빠른 성능과 높은 동시성을 처리할 수 있는 구조를 제공합니다.
각 엔드포인트는 다음과 같은 목적을 가지고 있습니다:
/health: 애플리케이션의 상태를 확인하는 간단한 비동기 엔드포인트./users/1/cache: Redis에서 사용자 정보를 비동기적으로 조회하여, 빠른 캐시 접근을 제공./users/{id}: MySQL 데이터베이스에서 사용자 정보를 비동기적으로 조회하여 실시간 데이터를 반환.
4. 성능 비교를 위한 도구
두 프레임워크의 성능을 비교하기 위해 JMeter 또는 Gatling 같은 성능 테스트 도구를 사용할 수 있습니다. 이러한 도구를 사용해 다양한 트래픽 환경에서 동기식(Synchronous)인 Spring MVC와 비동기식(Asynchronous)인 Spring WebFlux의 성능을 비교할 수 있습니다.
4.1. JMeter Thread Group
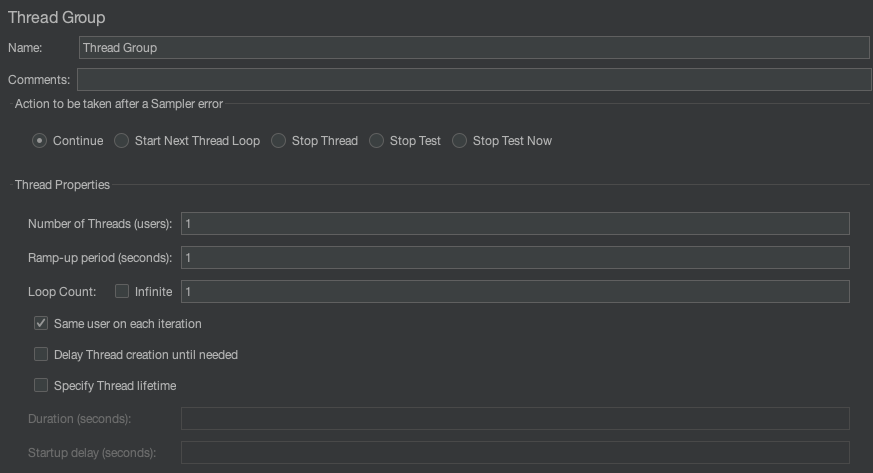
JMeter의 Thread Group은 부하 테스트 시나리오에서 가장 기본적인 구성 요소 중 하나입니다. Thread Group은 가상의 사용자를 나타내며, 사용자가 얼마나 많은 요청을 보내고 그 요청을 언제 보내는지에 대한 설정을 정의합니다. 이를 통해 실제로 여러 사용자가 웹 서버나 애플리케이션에 동시에 접속할 때의 성능을 측정할 수 있습니다.
Thread Group의 주요 설정 항목:
1. Number of Threads (users)
- 설명: 여기서 지정한 값은 동시 접속자 수를 나타냅니다. 예를 들어,
10으로 설정하면 JMeter는 10명의 가상 사용자를 동시에 시뮬레이션합니다. - 의미: 각 가상 사용자는 독립적인 스레드로 실행되어 서버에 요청을 보냅니다.
2. Ramp-Up Period (seconds)
- 설명: 스레드를 모두 실행하는 데 걸리는 시간을 의미합니다. 예를 들어,
Number of Threads가 10이고Ramp-Up Period가 20초라면, 20초에 걸쳐 10명의 가상 사용자가 순차적으로 실행됩니다. - 의미: 이 값이 0이면 모든 스레드가 동시에 시작되고, 값이 클수록 스레드가 더 천천히 시작됩니다. 서버가 한꺼번에 과부하되지 않도록 부하를 천천히 증가시키고 싶을 때 사용합니다.
3. Loop Count:
- 설명: 각 스레드가 요청 몇 번 반복할지 설정하는 옵션입니다.
- Forever 옵션을 선택하면 테스트가 수동으로 중지될 때까지 무한히 반복됩니다.
- 예를 들어,
Number of Threads가 10이고Loop Count가 5이면, 각 스레드는 5번의 요청을 보내므로 총 50번의 요청이 발생합니다.
4. Scheduler
- 설명: 스레드 그룹의 실행 시간을 일정하게 제어할 수 있습니다. 테스트가 얼마나 오래 실행되는지 시간을 지정할 수 있습니다.
Duration을 설정하면 특정 시간이 지나면 테스트가 자동으로 종료됩니다.Startup Delay는 테스트가 시작되기 전에 지연 시간을 설정하는 기능입니다.
5. Action to be taken after a Sampler error
- 설명: 요청이 실패했을 때 JMeter가 어떻게 처리할지 설정합니다.
- 예를 들어, 오류가 발생했을 때 테스트를 계속할지 중단할지를 설정할 수 있습니다.
4.2. JMeter Thread Group -> HTTP Request
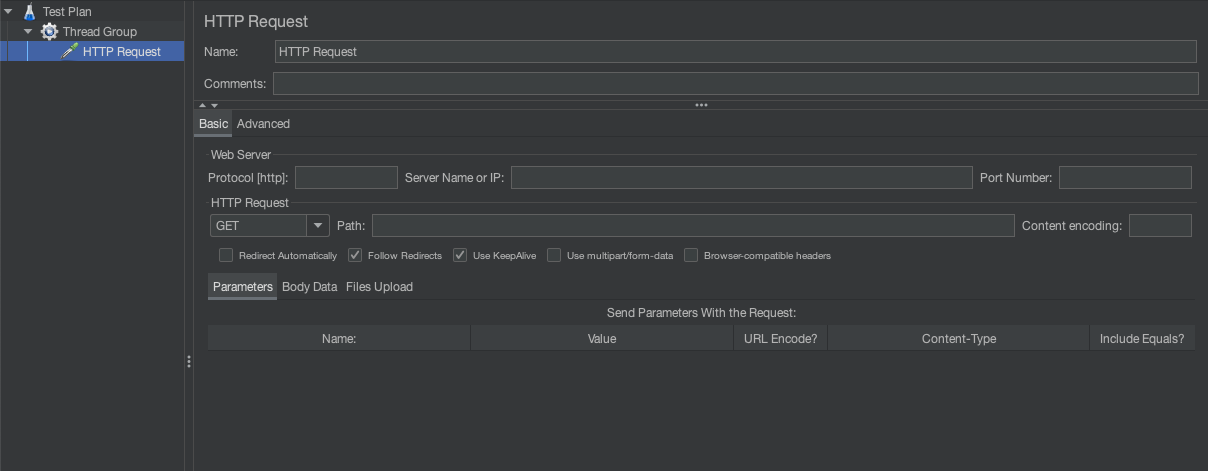
JMeter의 HTTP Request는 Thread Group 내에서 실제로 웹 서버 또는 API 서버에 요청을 보내는 가장 중요한 샘플러(Sampler) 중 하나입니다. JMeter에서 HTTP 요청을 통해 웹 애플리케이션이 특정 부하나 요청을 어떻게 처리하는지 테스트할 수 있습니다.
4.2.1. Server Name or IP:
- 설명: 여기에는 요청을 보낼 서버의 도메인 이름 또는 IP 주소를 입력합니다.
- 예:
www.example.com또는192.168.1.1 - 의미: 이 필드에 지정된 서버로 모든 요청이 전송됩니다.
4.2.2. Port Number:
- 설명: HTTP 요청이 전달될 포트 번호를 지정합니다.
- 기본값은 80 (HTTP) 또는 443 (HTTPS)입니다.
- 예: 웹 서버가 포트 8080에서 실행 중이라면, 여기서
8080을 입력합니다.
4.2.3. Protocol:
- 설명: 요청에 사용할 프로토콜을 지정합니다.
HTTP또는HTTPS를 선택할 수 있습니다. - 기본적으로 HTTP를 사용하며, 보안이 필요한 경우 HTTPS를 사용합니다.
4.2.4. Method:
- 설명: HTTP 요청에 사용할 메서드를 선택합니다.
- GET: 서버에서 데이터를 가져오는 데 사용됩니다.
- POST: 데이터를 서버로 전송할 때 사용됩니다.
- PUT, DELETE, OPTIONS 등도 지원됩니다.
- 예를 들어, 데이터를 조회할 때는 GET을, 서버에 데이터를 등록할 때는 POST를 사용합니다.
4.2.5. Path:
- 설명: 서버 내에서 요청할 경로를 지정합니다. 이는 도메인 이름 뒤에 붙는 경로입니다.
- 예:
/api/v1/users또는/index.html - 의미: 이 경로를 통해 특정 리소스 또는 API에 접근하게 됩니다.
4.2.6. Parameters:
- 설명: 요청과 함께 서버에 전달할 쿼리 파라미터 또는 폼 데이터를 설정할 수 있습니다.
- GET 요청의 경우 쿼리 스트링(
?key=value)으로 전달되고, POST 요청의 경우 요청 본문에 포함됩니다. - 예:
name=greg또는age=25 - 목적: 서버에 필요한 데이터를 요청하거나 특정 정보를 전송할 때 사용됩니다.
4.2.7. Body Data:
- 설명: POST나 PUT 메서드로 서버에 데이터를 전송할 때, 본문에 전달할 데이터를 작성할 수 있습니다. JSON, XML, 또는 기타 텍스트 형식으로 데이터를 전송할 수 있습니다.
- 예: JSON 데이터
{ "name": "greg", "age": 30 }
4.2.8. Files Upload:
- 설명: 파일을 서버에 업로드해야 할 경우, 여기서 파일 경로와 함께 업로드할 데이터를 지정할 수 있습니다.
4.2.9. Header Manager:
- 설명: 요청에 추가적인 HTTP 헤더를 설정할 수 있습니다. 예를 들어, 인증 토큰이나 Content-Type과 같은 값을 추가할 수 있습니다.
- Content-Type: 전송할 데이터의 타입 (예:
application/json). - Authorization: 인증이 필요한 API의 경우
Bearer 토큰또는Basic 인증헤더를 추가할 수 있습니다.
4.2.10. Timeouts:
- **설명**: 서버 응답 시간을 설정할 수 있습니다. 서버가 지정된 시간 내에 응답하지 않으면, 해당 요청이 실패한 것으로 간주됩니다.
- `Connect`: 서버 연결 시간 초과 설정.
- `Response`: 서버 응답 시간 초과 설정.4.2.11. Follow Redirects:
- **설명**: 요청에 대해 리다이렉션(HTTP 3xx 응답 코드)이 발생할 경우, JMeter가 자동으로 리다이렉션을 따라갈지 여부를 설정합니다.
- 예: 페이지가 다른 URL로 리다이렉션되었을 때, 이를 자동으로 처리하게 할 수 있습니다.4.2.12. Keep Alive:
- **설명**: HTTP 연결을 유지할지 설정합니다. 이 옵션을 활성화하면 동일한 연결을 여러 요청에 사용할 수 있습니다.
- **목적**: 성능을 높이기 위해 재연결을 방지하고, 하나의 연결로 여러 요청을 처리할 수 있습니다.5. JMeter 실습
참고로 jp@gc - Response Time Over Time, jp@gc - Transactions per Second는 플러그인을 찾아서 설치하고 다시 실행해주어야 합니다.
그리고 Thread Group -webflux는 우클릭 하여 disable 해주어야합니다. 그렇지 않으면 Thread Group - mvc를 실행 시 같이 실행됩니다.
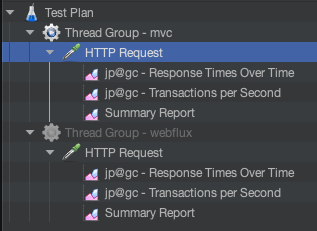
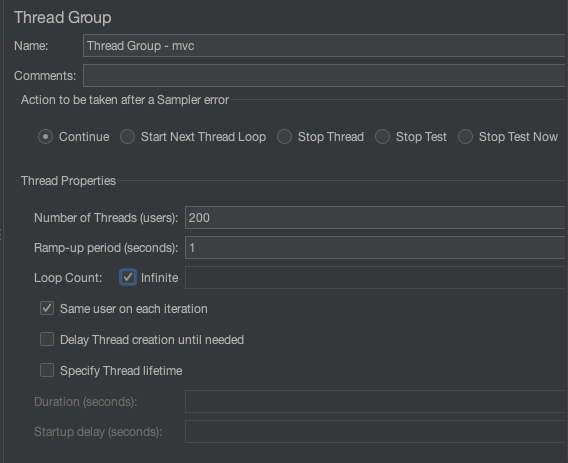
HTTP Request에서는 Path를 `/health` 로 엔드포인트를 설정하여 테스트 해보겠습니다.
5.1. 서버 빌드 및 실행
MVC
./gradlew build
java -jar build/libs/mvc-0.0.1-SNAPSHOT.jar각각의 프로젝트를 빌드하고 서버를 실행합니다.
/users/1 endpoint에 접근하여 동기통신이 MySQL DB와 통신 시 처리 되는 통계 정보를 확인 해 보겠습니다.
docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
31f05f8bf1bd mysql-r2dbc 86.08% 405.9MiB / 7.765GiB 5.10% 133MB / 133MB 115kB / 274MB 48
b29f75309e64 happy\_proskuriakova 0.24% 3.336MiB / 7.765GiB 0.04% 49kB / 38.9kB 0B / 32.8kB 6

webflux
./gradlew build
java -jar build/libs/webflux-0.0.1-SNAPSHOT.jar/users/1 endpoint에 접근하여 동기통신이 MySQL DB와 통신 시 처리 되는 통계 정보를 확인 해 보겠습니다.
docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
31f05f8bf1bd mysql-r2dbc 105.08% 442.4MiB / 7.765GiB 5.56% 219MB / 253MB 115kB / 274MB 57
b29f75309e64 happy\_proskuriakova 0.24% 3.336MiB / 7.765GiB 0.04% 49kB / 38.9kB 0B / 32.8kB 6

이 두 가지 테스트 결과는 각각 Spring MVC와 Spring WebFlux 애플리케이션의 성능을 비교하는 것으로 보입니다. 각 결과를 분석해 보면 아래와 같은 차이점을 발견할 수 있습니다:
5.2. MySQL 쿼리 시, 비교 분석
5.2.1. Spring MVC 테스트 결과
- # Samples: 190,898
- Average: 281 ms (평균 응답 시간)
- Min: 9 ms (최소 응답 시간)
- Max: 1,458 ms (최대 응답 시간)
- Throughput: 707.8/sec (처리율, 초당 처리된 요청 수)
- Received KB/sec: 169.15 KB/sec (수신된 데이터 양)
- Sent KB/sec: 85.01 KB/sec (송신된 데이터 양)
- Error %: 0% (에러 없음)
5.2.2. Spring WebFlux 테스트 결과
- # Samples: 583,869
- Average: 45 ms (평균 응답 시간)
- Min: 3 ms (최소 응답 시간)
- Max: 119 ms (최대 응답 시간)
- Throughput: 4,415.4/sec (처리율, 초당 처리된 요청 수)
- Received KB/sec: 607.97 KB/sec (수신된 데이터 양)
- Sent KB/sec: 530.36 KB/sec (송신된 데이터 양)
- Error %: 0% (에러 없음)
분석:
1. 처리율 (Throughput):
- Spring WebFlux의 처리율(4,415.4/sec)이 Spring MVC(707.8/sec)에 비해 훨씬 높습니다. 이는 WebFlux가 비동기 논블로킹 방식으로 동작하여 더 많은 요청을 동시에 처리할 수 있음을 의미합니다.
2. 평균 응답 시간 (Average Response Time):
- WebFlux의 평균 응답 시간(45 ms)이 MVC(281 ms)에 비해 훨씬 짧습니다. 이는 WebFlux가 더 빠르게 요청을 처리할 수 있음을 보여줍니다.
3. 최소/최대 응답 시간 (Min/Max Response Time):
- WebFlux는 최대 응답 시간(119 ms)이 비교적 짧은 반면, MVC는 1,458 ms로 최대 응답 시간이 훨씬 더 깁니다. 이는 MVC가 특정 상황에서 지연 시간이 더 길어질 수 있음을 시사합니다.
4. 전송된 데이터 양 (Received/Sent KB/sec):
- WebFlux는 수신(607.97 KB/sec) 및 송신 데이터(530.36 KB/sec) 모두에서 MVC보다 높은 값을 보여줍니다. 이는 WebFlux가 더 많은 요청을 처리하면서도 효율적으로 데이터를 주고받고 있음을 의미합니다.
5.4. Redis 쿼리 시, 비교 분석
/users/1/cache로 endpoint를 지정하여 MVC, Webflux 서버에 각각 테스트를 진행 합니다.
5.4.1. MVC


5.4.2. Webflux


성능 비교 분석
- Spring MVC:
- 평균 응답 시간은 18ms, 최대 응답 시간은 36ms로 상대적으로 안정적입니다.
- Throughput은 10,386.3 requests/sec으로 비교적 낮습니다.
- Spring WebFlux:
- 평균 응답 시간은 6ms로 Spring MVC보다 훨씬 빠릅니다.
- Throughput은 29,301.0 requests/sec으로 매우 높습니다.
- 자원 사용량:
- 두 서버 모두 MySQL 자원 사용은 비슷하게 유지되고 있지만, Redis는 WebFlux에서 상대적으로 높은 CPU 사용률을 보입니다. 이는 WebFlux의 비동기 처리가 더 많은 요청을 처리할 수 있음을 보여줍니다.
요약:
- Spring WebFlux는 Spring MVC보다 높은 Throughput과 더 낮은 응답 시간을 보여줍니다.
- 특히 WebFlux는 비동기 방식의 강점을 살려 훨씬 많은 요청을 처리하면서도 응답 시간에서 우위를 점하고 있습니다.
핵심 내용 요약
- 환경 구성:
- Docker를 이용해 MySQL과 Redis를 설정하고, 성능 테스트 환경을 준비했습니다.
- Spring MVC와 Spring WebFlux:
- Spring MVC는 동기식 처리 방식으로, 스레드를 할당하여 요청을 처리하며, 이는 상대적으로 간단하지만 높은 트래픽 상황에서는 성능이 떨어질 수 있습니다.
- Spring WebFlux는 비동기 논블로킹 방식으로 동작하여 더 높은 성능과 처리량을 제공하며, 특히 많은 동시 요청을 처리할 때 유리합니다.
- 성능 비교:
- Spring WebFlux는 Spring MVC에 비해 처리량(Throughput)이 월등히 높고, 평균 응답 시간도 훨씬 짧았습니다.
- Spring WebFlux는 더 많은 요청을 비동기적으로 처리하면서도 Redis 캐시와의 상호작용에서 높은 성능을 유지했습니다.
- 테스트 결과:
- Spring MVC는 평균 응답 시간이 18ms, Throughput이 10,386.3 requests/sec였습니다.
- Spring WebFlux는 평균 응답 시간이 6ms, Throughput이 29,301.0 requests/sec으로 WebFlux가 훨씬 뛰어난 성능을 보여주었습니다.
결론
이번 성능 비교에서 Spring WebFlux가 Spring MVC보다 훨씬 높은 성능을 보여주었습니다. 특히 비동기 처리 방식의 장점을 통해 더 많은 요청을 동시에 처리하고, 짧은 응답 시간을 제공함으로써, 높은 트래픽 상황에서 우수한 성능을 발휘했습니다. 따라서 트래픽이 많거나 실시간 처리가 중요한 애플리케이션에서는 Spring WebFlux가 더 적합하며, 간단한 동기식 애플리케이션에는 Spring MVC도 충분히 좋은 선택이 될 수 있습니다.
이 글을 통해 동기식과 비동기식 처리 방식의 차이와 성능 차이를 명확히 이해할 수 있었기를 바랍니다.
'프레임워크 > 자바 스프링' 카테고리의 다른 글
| 접속자 대기열 시스템 #4- 대기열 등록 API 개발 (6) | 2024.10.09 |
|---|---|
| BlockHound: Java 비동기 애플리케이션에서 블로킹 호출을 감지하는 도구 (6) | 2024.10.08 |
| Reactive Redis (1) | 2024.10.07 |
| webflux - R2DBC 실습 (0) | 2024.09.26 |
| Spring Webflux 실습 - 2 (0) | 2024.09.26 |